








Automated video restoration
Pixop Deep Restoration is our solution to enhancing degraded video. This automated solution can address common problems with digital video that would be either hard and/or time-consuming to address manually by a human operator using off-the-shelf video editing packages and plugins. In a nutshell, this AI filter can:
- Deblur upscaled video
- Reduce DCT compression artifacts
- Re-inject details into textures
Our model is based on a deep convolutional neural network (CNN) architecture that is trained on a mix of still frames and motion with the intention that it learns how to distinguish motion blur from the blur that results from upscaling the image. During the learning phase, the CNN is presented with thousands of image pairs of artificially degraded and perfect image patches. These degradations have been carefully engineered to resemble the type of artifacts commonly found in lossy compressed digital SD video.
We performed extensive validation on the trained model using several different video sources and genres.
How it works
Video is processed frame-by-frame using only a single video frame as input to generate the enhanced output.
- Initially the input frame is scaled to the desired resolution.
- An enhanced frame is produced from the output of the previous step via inference using our pre-trained neural network model.
Here are some zoomed-in 128x72 pixel before/after cropouts demonstrating the effects of applying Pixop Deep Restoration on SD Lanczos interpolated up to 1080p HD resolution (~2.75x magnification):

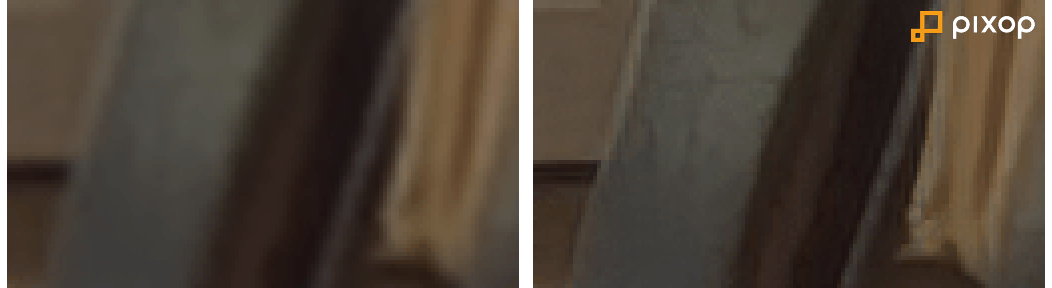


All four examples are extracts of frames from Screenbound Pictures' CI5: The New Professionals - episode 1 (16:9 aspect ratio SD PAL stored in 700x430 pixels).
A look inside a CNN
Courtesy of OpenAI Microscope, here is an abstract example that should give non-experts an intuition of what a CNN actually does. Starting at the first layer:

Contrast these with the feature activations of the last convolutional layer:

Notice how the network starts out by responding to basic patterns. These are then combined into increasingly more complex ones at deeper layers that eventually resemble well-known objects (such as a fish, a dog, etc.). This is an essential property that allows the CNN to generate a learned response to certain patterns, such as turning blurred out facial features into realistic-looking ones.
What type of video material is Pixop Deep Restoration best suited for?
Ideal for lossy-compressed digital footage that was shot with a bigger lens in any genre. An example would be producing a full HD version from the master of a TV series stored in SD PAL Sony XDCAM format.
Caveats
- The input must be relatively clean for the best results. To reduce the effects of noise (which is a common problem), Pixop Denoiser can be applied as a preprocessing step.
- The maximum output resolution is currently 1080 lines HD (1920x1080 pixels). If a UHD 4K version is desired, Pixop Super Resolution can be used in a two-step pipeline process to produce the final upscaled 4K version using the deeply restored HD as the input.
- Minor variations in some colors in the output when compared to the input might be observed.
- A very slight thinning of some objects as a result of the deblurring/deconvolution feature might be observed in certain cases.
- Not suited for extremely low-bitrate video recorded from webcams, for example.
- Magnification outside the 2x-3x range is not guaranteed to give good results.
Processing speed
Expected runtime performance (frames per second (FPS) is stated as well as the time to process 1 hour of PAL video in parentheses):
- HD - 9.5 FPS (2.5 hours)
Note that these numbers assume H.264 encoding being used. Very CPU-intensive codecs like H.265 and/or extremely high bitrates will yield less performance.