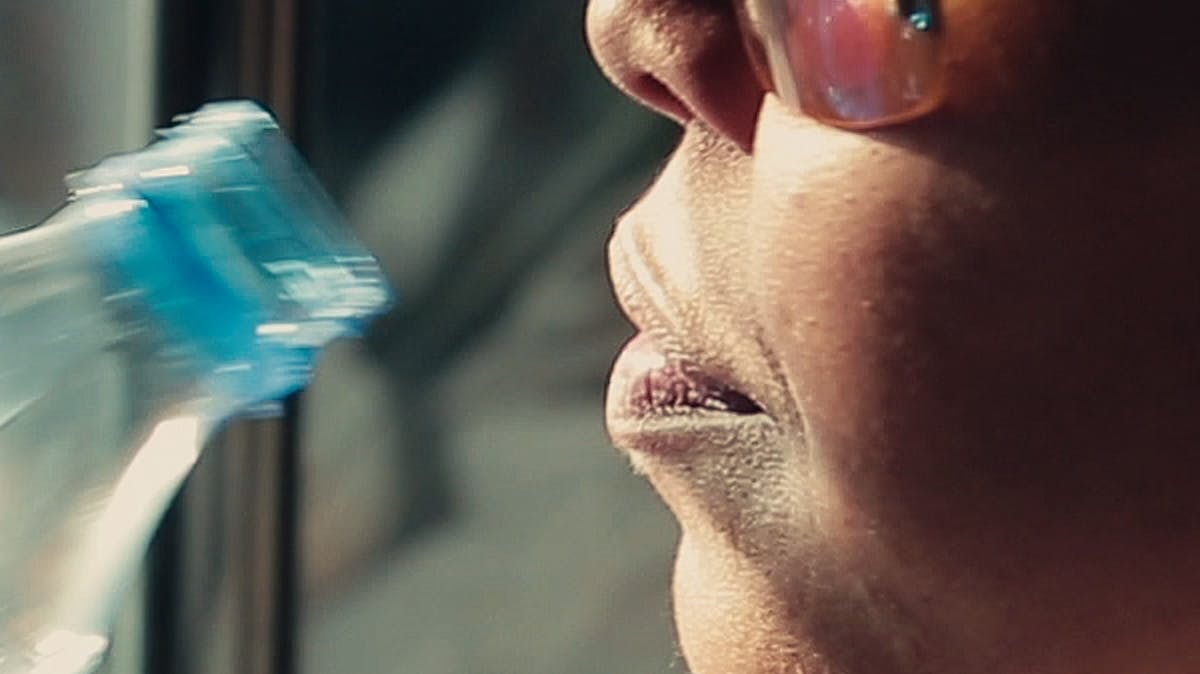




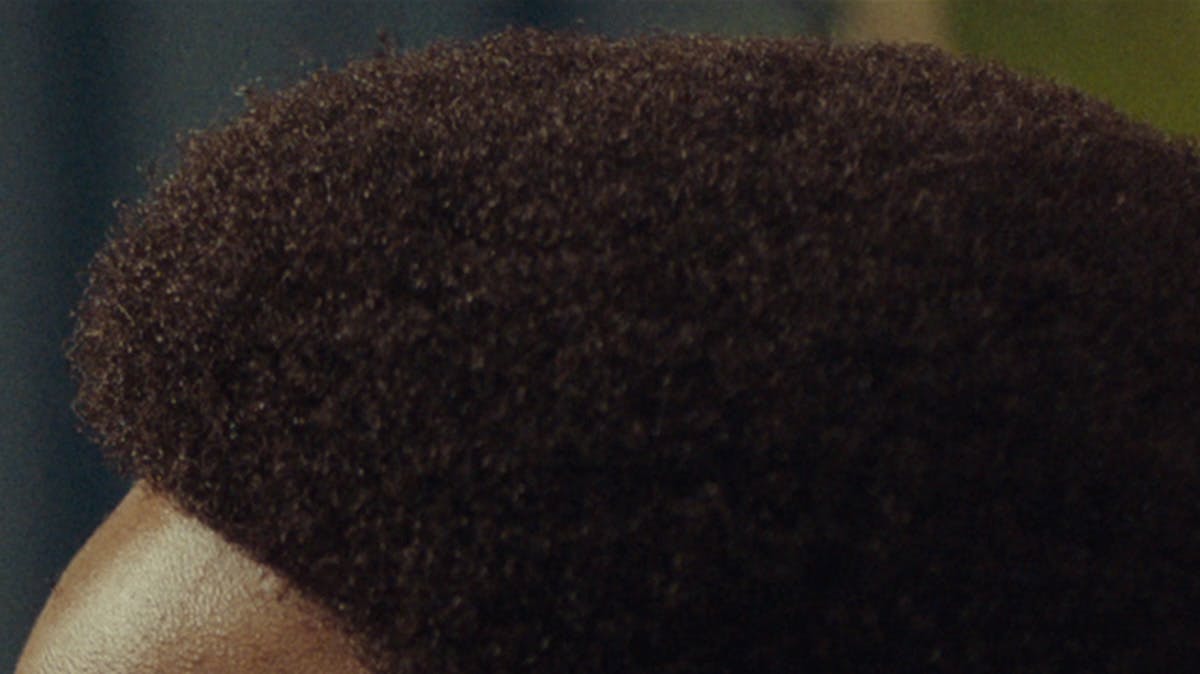





Better looking upscaling
Classic interpolation techniques make edges, textures and abstract shapes look blurry and aesthetically unpleasing. Interpolation is a basic, computationally cheap technique, which has the inherent drawback that no enhancement is done. Super-resolution technology, either on individual images or video, has progressed a lot in recent years and yields significantly better results compared to interpolation.
With “PIXSR” (“Pixop Super Resolution”), we have created a patch-based image processing technique that incorporates machine learning in order to produce high-quality versions of low-resolution videos. Our method is largely inspired by “RAISR” (“Rapid and Accurate Image Super Resolution”), the revolutionizing super-resolution technique developed by Google back in 2016. RAISR was motivated by a desire to save transmission bandwidth on Google+ for mobile devices. Its speed/image quality/versatility design trade-off makes RAISR a really interesting candidate for video super-resolution, as well.
PIXSR, which has distinct algorithmic differences and improvements compared to RAISR (e.g. by computing gradients more robustly), is capable of producing visually convincing results on video.
How it works
To upscale video from, for example, SD to HD and HD to UHD 4K, Pixop’s PIXSR filter is trained on patches from corresponding low-res and high-res image pairs, according to three edge features:
- Angle: the direction of an edge
- Strength: the edge sharpness
- Coherence: a measure of edge directionality
A lookup hash table is then generated based on these features, the modulo of the pixel position, and a combination of least-squares solvers.
Below is a visualization of PIXSR 3x filters for a specific pixel position, learned from about 44 million patches of 11x11 pixels.

It is only a small subset of learned filters for 3x super-resolution. The intensity and color of each kernel value in this visualization designates the weight and sign (red for positive feedback, blue for negative feedback).
Notice, from left to right, that filters have a selective response to the underlying edge being reconstructed; i.e., as the angle of the edge changes, the gradient angle of the filter rotates accordingly. Similarly, as the strength increases, the sharpness of the filters increases, and the directionality of the filter increases with rising coherence.
At run-time, PIXSR selects and applies the most relevant learned linear filter. When these filters are applied, they recreate details that are comparable to the original (while also avoiding aliasing issues like Moire patterns and jaggies), i.e., a significant improvement to interpolation.
Sharpness boosting
A powerful advantage of the filter learning approach is the possibility to bake sharpness boosting into the learned filters. This allows, e.g., clarity to be enhanced during run-time upscaling — a highly useful property in the context of video in order to compensate for degradations such as blur and compression.

The learned filters used to produce the right image above include sharpness boosting in the training phase. Fine details, like body hair and wood textures for example, stand out significantly clearer as a result.
You might be wondering whether it is possible to get similar results by simply sharpening an interpolated image. However, it does not look nearly as good. The ML approach used in PIXSR for learning “optimal sharpening” is superior as it respects image gradients.
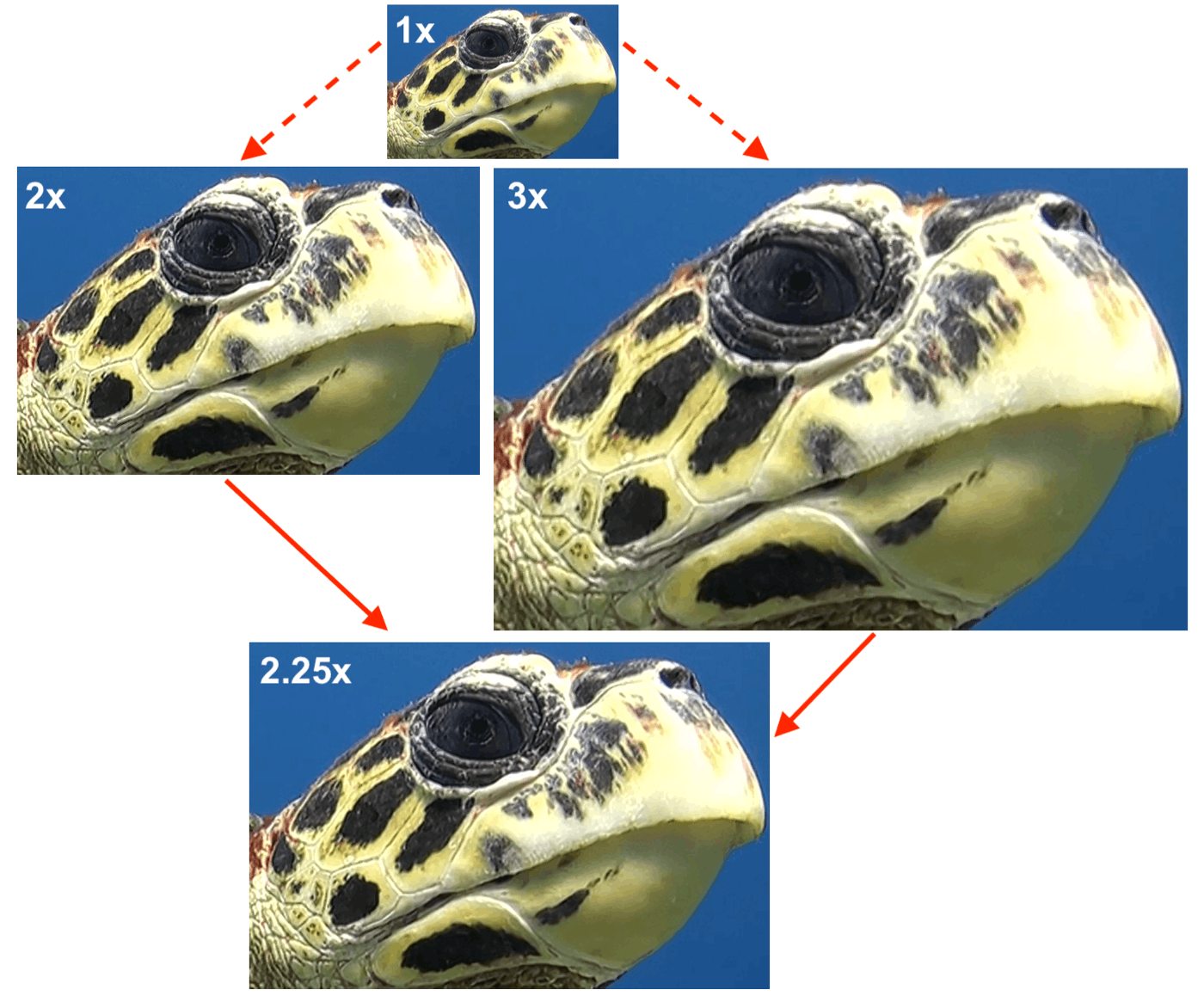
Fractional upscaling
Fractional upscaling factors are currently achieved via trilinear interpolation between super-resolved versions of the low-resolution image (nearest integer factors — in this case 2x and 3x).
This is an example of 2.25x upscaling achieved by combining intermediate 2x and 3x super-resolved results.
What type of video material is Pixop Super Resolution best suited for?
Ideal for footage shot with a bigger lens using a good quality digital camera sensor stored without too much lossy compression and synthetic content. Examples could be video produced in the HD era, stock footage, animated movies (2D or 3D) and so on.
Caveats
- Since no deconvolution is performed, PIXSR is not suitable for recovering details in degraded footage
- Designed to work on square pixels only. Note that if the storage aspect ratio and display action ratio differs, the video will be pre-upscaled to match the display aspect ratio.
- Only the luminosity channel is Super Resolution processed, chroma channels are bicubic interpolated (the human eye is much less sensitive to chromatic changes).
Processing speed
Expected runtime performance for three popular target resolutions (frames per second (FPS) is stated as well as the time to process 1 hour of PAL video in parentheses):
- HD - 35 FPS (40 minutes)
- 4K - 12 FPS (2 hours)
- 8K - 3 FPS (8 hours)
Note that these numbers assume H.264 encoding being used. Very CPU intensive codecs like H.265 and/or extremely high bitrates will yield less performance.