Worldwide, millions of hours of video are being watched daily from a variety of sources such as live streaming, cable TV, Blu-Ray and DVD. With the widespread presence of HD, UHD 4K, and recently 8K, televisions, the demand for high-quality versions of low-resolution video has never been greater. However, many of these videos are either limited by the resolution they were originally acquired in, or degraded to accommodate the requirements for specific display devices and to reduce network bandwidth.
When rendering lower resolution video practically all display devices are currently able to perform interpolation (bilinear, bicubic, Lanczos, etc.). This makes edges, textures and abstract shapes look blurry and aesthetically unpleasing. Interpolation is a basic, computationally cheap technique, which has the inherent drawback that no enhancement is done.
It is not cool when your brand new BMW is stuck in first gear. Sure, the car runs, but it is unsatisfying to say the least. As video consumers we should demand video to look as awesome as possible on our devices, but unfortunately the present state of affairs is that we have come to lower expectations for e.g. older content that wasn’t produced for our modern, high pixel count displays. The reason being that not many solutions exist to the problem of increasing resolution after the final cut and digital mastering.

Photo credit: Denise Jans.
Re-digitization and restoration of film stock is a good option in terms of achieving optimal visual results (e.g. Peter Jackson’s “ They Shall Not Grow Old “). Normally this requires manual handling which comes with a hefty price tag. ML/AI powered tools provide ways of reducing cost in the future, but today these projects very much rely on manual labor.
Generally footage is not recorded on film because the storage medium and handling is too expensive for most use cases. The past 20 years most footage is mostly shot and mastered digitally, and analog tape video recording for TV production has a history dating back to the late 1950s. Unfortunately recreating the original signal at any resolution is a mathematical impossibility (unlike what you would believe by watching CSI and Hollywood movies), but certainly there must be ways to improve upon basic interpolation without breaking the bank. If there is an untapped potential which improves the viewer experience why not go for it?
Super Resolution to the rescue
Super-resolution technology, either on individual images or video, has progressed a lot in recent years and yields significantly better results compared to interpolation. It’s a very attractive research topic and more than 600 papers has been published over the last two decades. These techniques to a certain extent require information to be hallucinated. Most methods are computationally very expensive, and while feasible in a research setting for image processing they are either too slow or not designed for video. Commercial video super-resolution products using fast methods do exist today as plugins for video editing tools and in high-end UHD TV sets, but they are still not common.

Photo credit: Chris Murray.
Deep Learning techniques such as end-to-end trained Generative Adversarial Networks (GANs) are slowly starting to become state-of-the-art for video, but it is still very much a topic of active research in terms of dealing with issues like temporal consistency. As an example, exciting work has been published very recently by researchers at fast.ai on combining “decrappification” and “deoldification” with Super Resolution. Their results are exciting and shows high quality, high resolution video can now be produced from seriously degraded footage.
However, the major disadvantage of Deep Learning based approaches today is the fact they are not straight-forward to deploy in a production setting. These techniques require a lot of (GPU) memory which becomes an issue when generating UHD 4K and 8K output.
A practical approach
With “PIXSR”, “ PIXop Super Resolution” (internally known as “PABSR1”) Pixop has created a patch-based image processing technique that incorporates machine learning in order to produce high-quality versions of low-resolution videos. Our method is largely inspired by “RAISR” (“ Rapid and Accurate Image Super Resolution”), the revolutionizing super-resolution technique developed by Google back in 2016. RAISR was motivated by a desire to save transmission bandwidth on Google+ for mobile devices. Its speed/image quality/versatility design trade-off makes RAISR a really interesting candidate for video super-resolution, as well.
It’s been quite a journey, though. As as first attempt, I worked for several months back in 2017 to get a full implementation of RAISR running in plain Julia code. Although the RAISR paper is awesome and describes most aspects in great detail, it turned out to be challenging to get all bells and whistles working right.
Early prototype work from 2017 showing a working implementation of RAISR in Julia for video enhancement. Processing all the frames for this short video took more than 36 hours.
Early prototype work from 2017 showing a working implementation of RAISR in Julia for video enhancement. Processing all the frames for this short video took more than 36 hours
PIXSR, which has distinct algorithmic differences and improvements compared to RAISR (e.g. by computing gradients more robustly), when implemented in optimized C++ including various AVX2 intrinsics running on AWS infrastructure, is capable of producing visually convincing results on video. By processing individual frames separately it can produce around 35 frames per second of HD video using CPUs only. This makes video super-resolution practical as a 50 minutes episode of a TV series can be processed in about half an hour.
Trained filters
PIXSR filters are trained on patches from corresponding low-res and high-res image pairs, according to three edge features:
- Angle, the direction of an edge
- Strength, the edge sharpness
- Coherence, a measure of edge directionality
A lookup hash table is then generated based on these features, the modulo of the pixel position and a combination of least-squares solvers.
Below is a visualization of PIXSR 3x filters for a specific pixel position, learned from about 44 million patches of 11x11 pixels. The multi-threaded training process takes just 10 minutes thanks to the use of CUDA-accelerated OpenCV
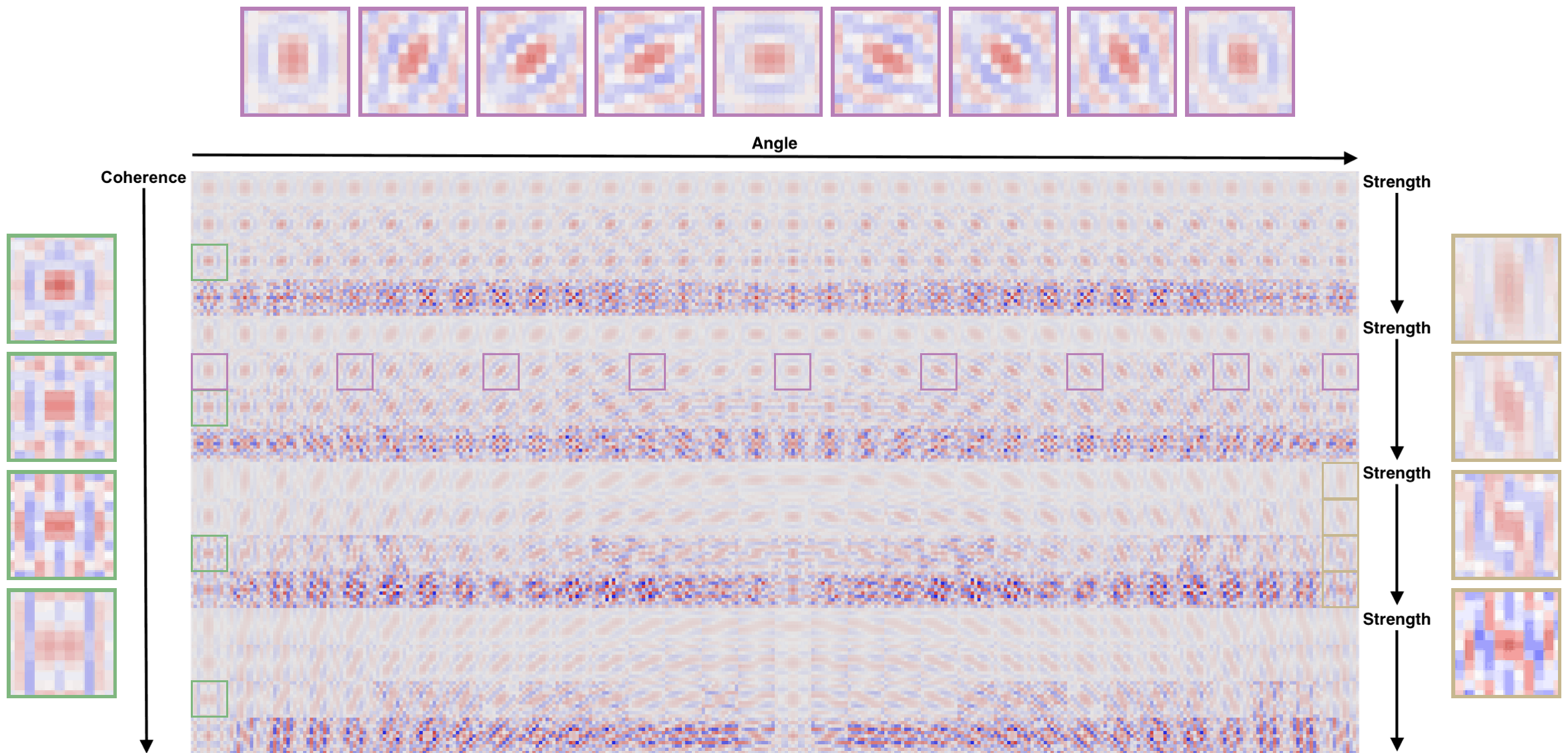
A subset of learned filters for 3x super-resolution. The intensity and color of each kernel value in this visualization designates the weight and sign (red for positive feedback, blue for negative feedback).
Notice how, from left to right, that filters have a selective response to the underlying edge being reconstructed, i.e. as the angle of the edge changes, the gradient angle of the filter rotate accordingly. Similarly, as the strength increases, the sharpness of the filters increases, and the directionality of the filter increases with rising coherence.
At run-time PIXSR selects and applies the most relevant learned filter. When these filters are applied, they recreate details which are comparable to the original (while also avoiding aliasing issues like Moire patterns and jaggies), i.e. a significant improvement to interpolation.
Lights, camera, action!
Some examples of PIXSR 2x, 3x and 4x output on croppings of actual video frames (Shutterstock footage)
2x upscaling



Examples of 2x upscaling — from left to right: the original low resolution cropping (300x200), bicubic interpolation, PIXSR.
3x upscaling



Examples of 3x upscaling — from left to right: the original low resolution cropping (200x133), bicubic interpolation, PIXSR.
4x upscaling



Examples of 4x upscaling — from left to right: the original low resolution cropping (150x100), bicubic interpolation, PIXSR.
Sharpness boosting
A powerful advantage of the filter learning approach is the possibility to bake sharpness boosting into the learned filters. This allows e.g. clarity to be enhanced during run-time upscaling; a highly useful property in the context of video in order to compensate for degradations such as blur and compression.


PIXSR 2x upscaling: plain vs sharpness boosted. The learned filters used to produce the right image include sharpness boosting in the training phase. Fine details like e.g. body hair and wood textures stand out significantly clearer as a result.
You might be wondering whether it is possible to get similar results by simply sharpening an interpolated image. However, it does not look nearly as good from my testing. The ML approach used in PIXSR for learning “optimal sharpening” is superior as it respects image gradients.
Fractional upscaling
Fractional upscaling factors are currently achieved via trilinear interpolation between super-resolved versions of the low resolution image (nearest integer factors, in this case 2x and 3x).
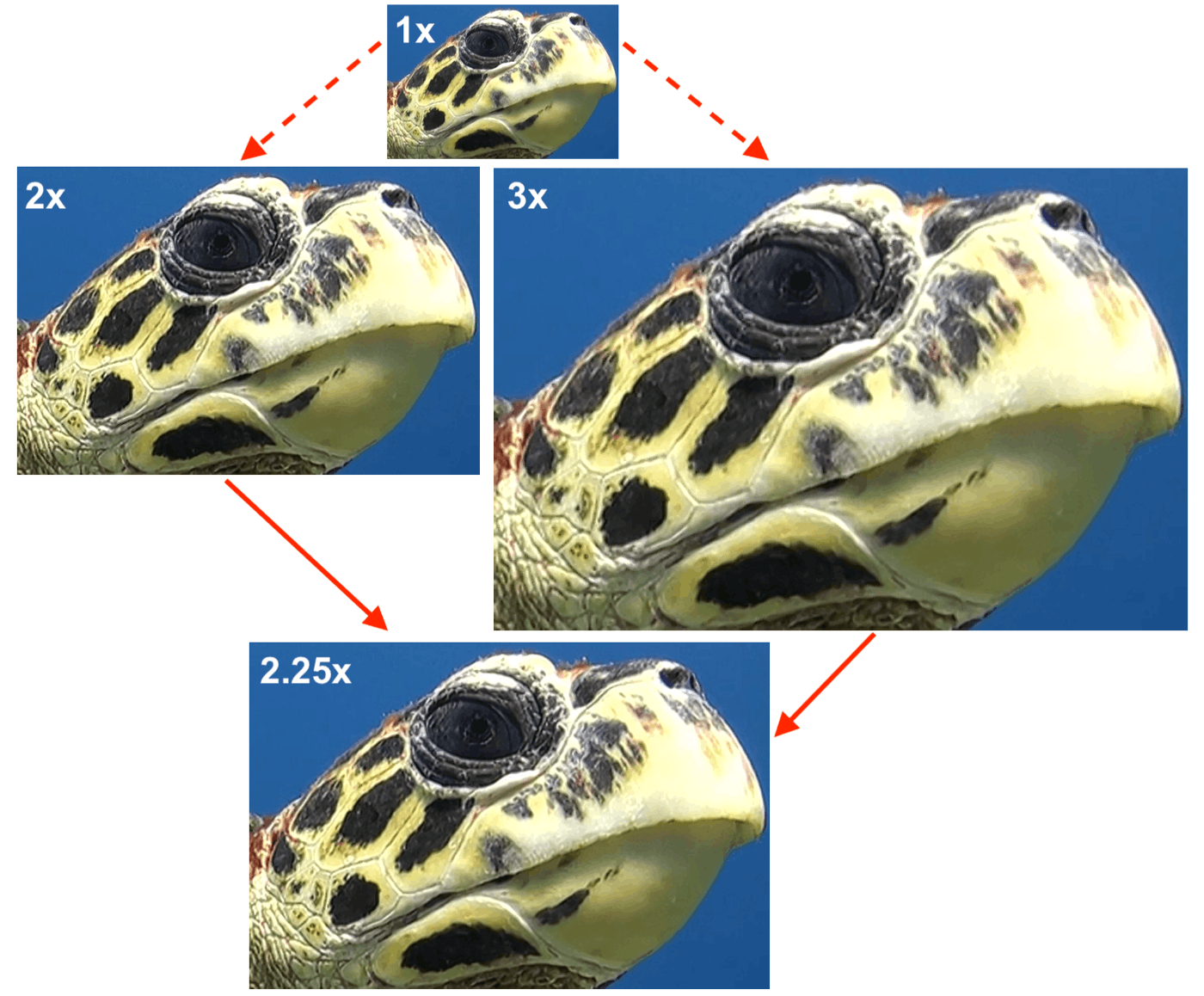
2.25x upscaling achieved by combining intermediate 2x and 3x super-resolved results.
Try it yourself
Additional interactive examples can be found on our website, and PIXSR can be tested at no cost as part of Pixop Platform’s beta tester program.
Go to: pixop.com.