So, a little while ago we decided to publish a little series exploring:
- What video resolution is
- What the most common display resolutions are
- A little bit of the history of display technology
- The technology behind video resolution
- What upscaling and downscaling are
- The different kinds of upscaling algorithms
- Why UHD resolutions are crucial in the age of streaming and
- How you can use Pixop to upscale your SD videos so that they look like they were natively shot in UHD.
In part one of this series, we covered the first three points: we briefly defined what video resolution is, laid out the most common kinds of video resolutions and took you through a condensed history of how we got from H.120 (176 x 144 pixels) in the 1980s to UHD 8K (7680 × 4320 pixels) today.
We wanted to save the technical explainer for its own section, so, here, we’ll focus on explaining the technology behind display resolution. But don’t worry — we’ll try our best from becoming overly technical and explain things in as simple a way as possible.
Display technology
As mentioned in the first part of this series, put simply, video resolution is the number of pixels each frame of a video contains, represented by two numbers: the number of horizontal pixels and the number of vertical pixels. So, a display resolution of 7680 × 4320 means that that screen contains 33,177,600 individual pixels
But in order to begin to understand what that means, we first have to understand what pixels are and how they produce the images that you see on your screens every day.
Different arrangements of pixels on types of display screens. Credit: Pengo.
What is a pixel?
A pixel (or picture element) is the smallest unit of a digital image or graphic that can be displayed and represented on a digital device. Many pixels are combined to give rise to pictures, videos, text — basically, everything you can see on a screen, you can see thanks to pixels coming together in infinite combinations to produce shapes, colors and textures.
In some contexts, like TV screens and computer monitors, the easiest way to think of pixels is like colored dots that come together to give rise to the image.
In the context of digital cameras, we have to conceptualize pixels slightly differently. We’ve already gone into greater detail about this in our image noise article, but here’s a quick refresher: the most common type of camera sensor is a CCD sensor, aka a charge-coupled device. These devices have a network of capacitors that are engineered to detect and ‘collect’ electrons hitting them to give rise to different colors and intensities of light. When an image is projected onto the lens, each capacitor accumulates an electric charge proportional to the light intensity at that location.
These charges are then compiled and dumped into a charge capacitor, which converts them into a series of voltages. The voltages, in turn, are sampled, digitized, stored and processed to give rise to the final image.
The more of these capacitors a camera’s sensor has, the higher the capture resolution (with the inherent drawback that more noise is also generated). This is simply because it has more information to work with, and more information means brighter colors, sharper details and better looking imagery.
But hold on — cameras like that are expensive to buy. And what about footage shot years ago on older equipment that wasn’t quite as advanced as what’s readily available to the average consumer these days? Is there any hope of salvaging any of it? And if so, how?
Turns out, there is! Everyone, say hello to upscaling technology.
What is upscaling?
Upscaling is the process of taking something that was captured in a lower resolution and ‘scaling’ that resolution into something different. The ‘up’ in ‘upscaling’ refers to improving the resolution, but you can also downscale something using technology based on the same principles.
For the longest time (and most commonly still) upscaling was bundled into the host of processes performed by consumer electronics like televisions and computers. The situation usually played out like this: if older footage shot in a lower resolution had to be broadcast on hi-res screens, these screens had hardware chips (in the case of TVs) and GPUs (in the case of computers) that typically employed the most rudimentary forms of upscaling, called bilinear and bicubic interpolation, to ‘stretch’ the image across the screen, oftentimes leading to blurry video.
Things have come a long way since then, however, with more and more upscaling being powered by AI and hosted on the cloud (like Pixop, for example). More and more broadcasters and production companies are also upscaling older footage before it is broadcast on consumer screens.
There are several different approaches to upscaling; we'll detail the most common in the next section.

Pixop Super Resolution upscaling versus other popular methods — examples
Different upscaling methods
Nearest neighbor interpolation
This is the simplest approach to upscaling. With most other upscaling methods, average values or intermediate values of neighboring pixels are calculated to give rise to more pixels, resulting in the upscaled image. Nearest neighbor interpolation, on the other hand, simply determines the “nearest” neighboring pixel and assumes the intensity value of it to give rise to the upscaled output.
Bicubic Interpolation
Bicubic interpolation uses cubic splines and other polynomial techniques to sharpen and enlarge digital images. There are two primary kinds of bicubic interpolation: adaptive and non-adaptive. Adaptive techniques account for and adapt to differences in the source material, whereas non-adaptive methods treat all pixels equally. Interpolation involves extrapolating unknown data from known data. So, for example, if we want to take a video originally shot in SD and upscale it to HD, we need to approximate the value of the new pixels needed by sampling surrounding pixels. Bicubic interpolation is superior to both bilinear and nearest-neighbor interpolation as it considers 16 pixels (a 4 x 4 grid) rather than 4 pixels (a 2 x 2 grid). This makes the upscaled output smoother and less prone to interpolation artifacts.
Lanczos resampling
In this method, input samples of the original image are filtered through a Lanczos kernel — which is a mathematical process — to reconstruct them. Once this process has been completed, the interpolation is implemented using a mathematical convolution function known as the sinc function.
Deep Convolutional Neural Networks
Convolutional Neural Networks are deep learning algorithms that are inspired by the organization of neurons on the human cortex, which makes them ideal for applications such as image recognition and natural language processing. They reduce the input image into a series of smaller matrices and upscale the image by feeding the input into a convolutional layer, a pooling layer and finally a classification layer known as a fully connected layer.
Generative adversarial networks
A Generative Adversarial Network or GAN is a type of Deep Convolutional Neural Network designed by Ian Goodfellow and his colleagues in June 2014. Two neural networks contest with each other in a game (in the form of a zero-sum game, where one agent's gain is another agent's loss). In simple terms, and in relation to upscaling, one neural network, called the ‘generator’ is tasked with ‘studying’ thousands of hi-res/low-res image pairs and ‘learning’ how to faithfully recreate from low-res to hi-res. Meanwhile, the other neural network, called the ‘discriminator’, is specifically tasked with ‘discriminating’ between the original hi-res version of the image pair and the one generated by the generator. The two neural networks play off each other in this way which enables the model to learn in an unsupervised manner.
Pixop’s Super Resolution Upscaling
All the most common upscaling techniques these days, as mentioned previously, are carried out using hardware chips and GPUs on consumer electronics like computer screens and televisions. These techniques apply interpolation methods to upscale digital images and videos, making them less than ideal because they make edges, textures and abstract shapes look blurry and unappealing. Despite this, they are still the most commonly used because they are a computationally cheap technique, with the inherent drawback that no enhancement is done.
In contrast to classic interpolation methods, super resolution technology is capable of upscaling an image and enhancing it, while avoiding the pitfalls of blurry details and unappealing images, which is why we’ve committed to using it at Pixop with our ML Super Resolution filter.
With “PIXSR” (“Pixop Super Resolution”), we have created a patch-based image processing technique that incorporates machine learning in order to produce high-quality versions of low-resolution videos. We've based this on the iterative least squares method, which is a completely different paradigm and architecture compared to deep learning.
Our method is largely inspired by “RAISR” (“Rapid and Accurate Image Super Resolution”), the revolutionizing super-resolution technique developed by Google back in 2016. RAISR was motivated by a desire to save transmission bandwidth on Google+ for mobile devices. However, its speed/image quality/versatility design trade-off makes RAISR a really interesting candidate for video super-resolution, as well.
PIXSR, which has distinct algorithmic differences and improvements compared to RAISR (e.g. by computing gradients more robustly), is capable of producing visually convincing results on video.
How Pixop’s ML Super Resolution algorithm works
Pixop’s Super Resolution filter can upscale input from SD all the way up to UHD 8K. To do so, we’ve trained in on patches of corresponding (hi-res and low-res) image pairs according to three edge features:
- Angle: The direction of an edge
- Strength: The edge sharpness
- Coherence: a measure of edge directionality
A lookup hashtable is generated based on these features, plus the modulo of the pixel position, and a combination of least-squares solvers. From this, a number of learned linear filters are generated and the Pixop Super Resolution algorithm selects the most relevant one at runtime.
Below is a visualization of the process for a specific pixel position, learned from about 44 million patches of 11x11 pixels. The intensity and color of each kernel value in this visualization designates the weight and sign (red for positive feedback, blue for negative feedback).
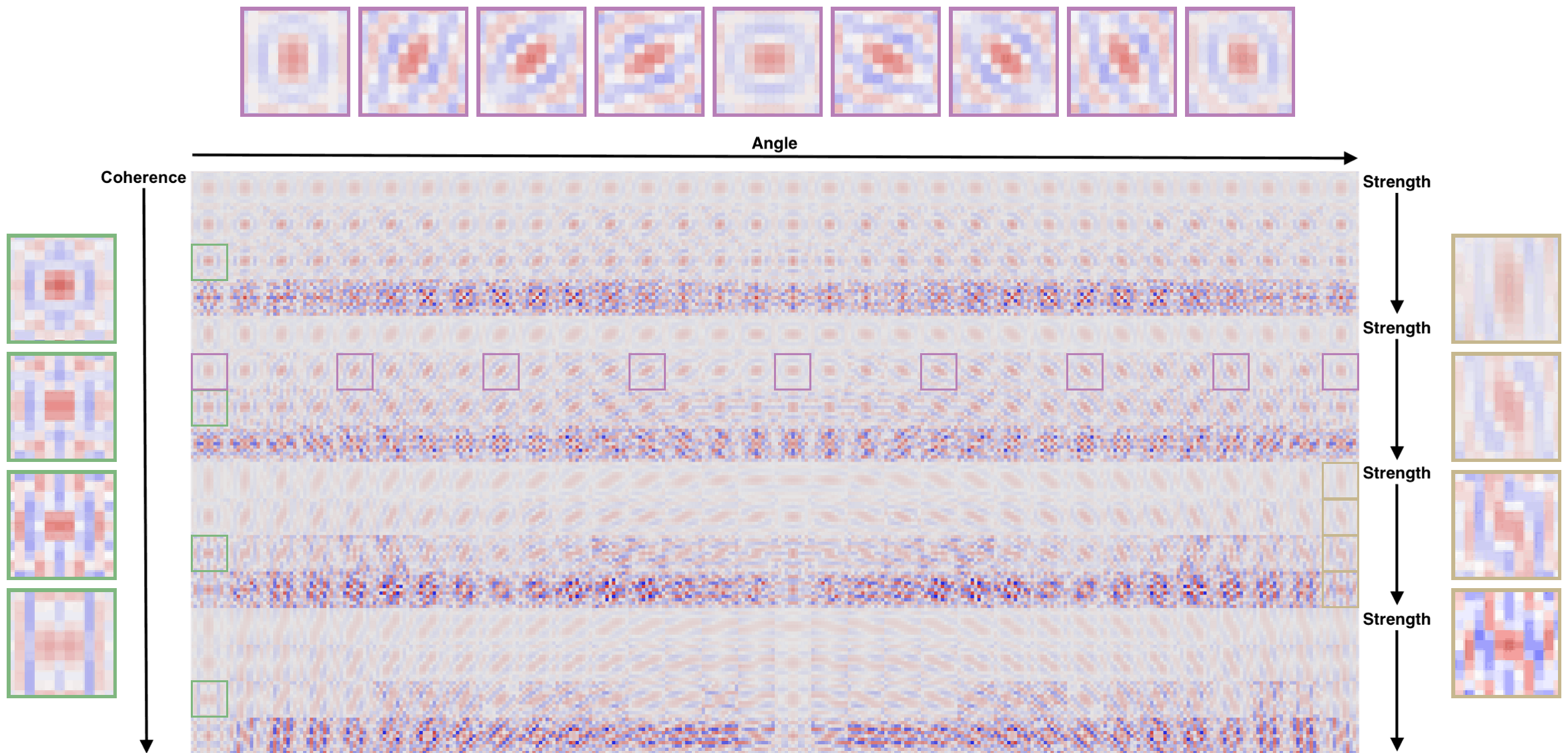
A lookup hash table learned from about 44 million patches of 11x11 pixels.
Notice, from left to right, that filters have a selective response to the underlying edge being reconstructed; i.e., as the angle of the edge changes, the gradient angle of the filter rotates accordingly. Similarly, as the strength increases, the sharpness of the filters increases, and the directionality of the filter increases with rising coherence.
Advantages of Pixop Super Resolution
Our super resolution algorithm has a number of advantages. Not only is it easy to use, essentially doing all the work for you, but it also:
- Allows you to upscale the original footage by up to either 4x or UHD 8K
- Produces an accurate and faithful high-resolution representation of the source.
- Optionally allows sharpness to be improved, making the output subjectively more aesthetic.
- Achieves its results by drawing on a machine learning memory bank of thousands of filters.
Now that we’ve covered the more technical aspects of video resolution and different types of video upscaling algorithms, in part 3 of this series, we’ll take you through why upscaling your archives is a good idea and how you can do just that with Pixop’s ML Super Resolution filter.